By combining large language models and multimodal datasets, researchers are revolutionizing the search for novel materials, addressing biases, and advancing the discovery of superior materials for applications like solar cells and batteries.
 Research: 1.5 million materials narratives generated by chatbots
Research: 1.5 million materials narratives generated by chatbots
In a paper published in the journal Scientific Data, researchers addressed the limitations of artificial intelligence (AI) models in exploring materials by creating a dataset of exactly 1,453,493 natural language-material narratives from four major publicly accessible databases: OQMD, Materials Project, JARVIS, and AFLOW. The narratives were generated using ab initio calculations, ensuring a more balanced representation of materials across the periodic table.
Based on these ab initio calculations, these narratives were evaluated by human experts and Generative Pre-trained Transformer 4 (GPT-4) for factual accuracy, language structure, and content depth. Both evaluations showed similar scoring; however, human assessments highlighted a noticeable lag in content depth. The study underscored the potential of integrating these multimodal data sources with large language models (LLMs) to enhance solid-state material discovery.
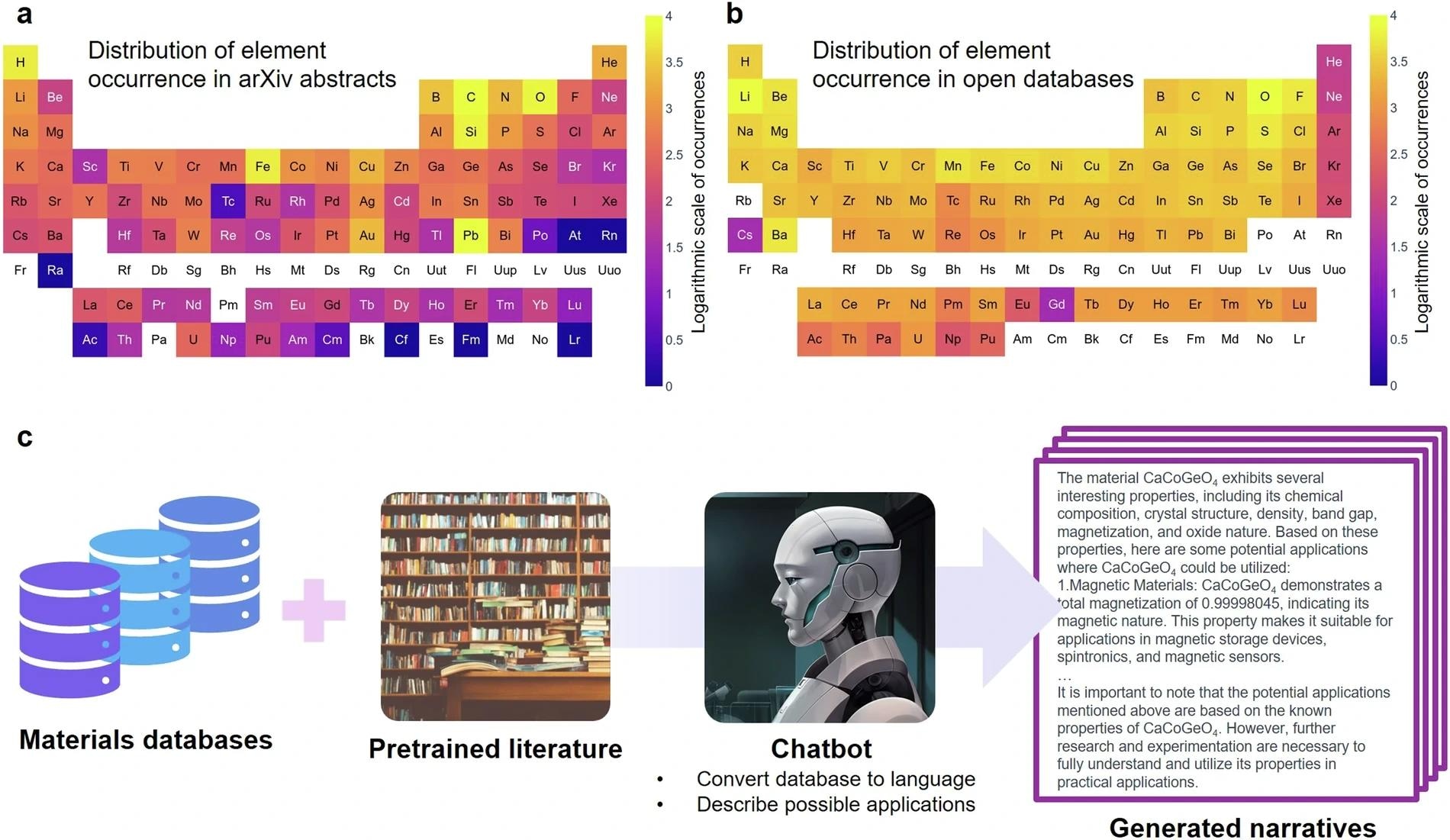 Overall data synthesis framework proposed in this work. (a) Distribution of chemical elements invoked in materials studied in the materials research literature. (b) Distribution of chemical elements in publicly accessible databases that are mostly generated by ab initio calculations. (c) The proposed framework that extracts knowledge about materials science to overcome the discrepancy between the materials studied in research and those available in public databases.
Overall data synthesis framework proposed in this work. (a) Distribution of chemical elements invoked in materials studied in the materials research literature. (b) Distribution of chemical elements in publicly accessible databases that are mostly generated by ab initio calculations. (c) The proposed framework that extracts knowledge about materials science to overcome the discrepancy between the materials studied in research and those available in public databases.
Background
The significance of materials in human history is undeniable, with each major era often named after the material that defined it, such as the Bronze Age or Iron Age. The search for novel materials has become even more critical in the face of the climate crisis, which has spurred the exploration of new materials for applications like solar cells and batteries. Despite advances in materials discovery through first-principles (ab initio) calculations and the increasing application of generative AI models, analysts faced limitations due to biases in conventional, common-core language models that favored "hot materials."
Challenges included this bias toward frequently studied "hot materials," which led to the neglect of lesser-known but potentially superior materials for specific applications. This issue hinders breakthroughs in discovering new materials that could offer better technological functionalities.
Addressing Material Biases: Methodology
The methods employed in this study aimed to address and correct the biases in material representation within common-core text corpora. To make these biases visible, the team employed data from publicly available resources, like arXiv, and analyzed over 284,815 abstracts from the ‘cond-mat’ category. They noted a predominance of familiar oxides like iron and copper in the literature, while a more balanced distribution of materials appeared in ab initio databases such as the Materials Project and the Open Quantum Materials Database (OQMD). This stark contrast highlights the need for balanced data input for AI models.
The robust narrative generation process was conducted using a sophisticated data collection pipeline implemented in Python and PyTorch, leveraging high-performance computing resources. This system utilized multiple material properties, such as band gaps and formation energy per atom, from repositories like the Joint Automated Repository for Integrated Simulations (JARVIS). These properties were calculated using density functional theory (DFT). Despite inconsistencies across different databases, key properties, including both scalar physical quantities and categorical data, were heuristically selected and processed to facilitate meaningful narrative generation.
To address these inconsistencies, the team developed and trained a graph neural network (GNN) model capable of extrapolating material properties across multiple databases. The model, which was E(3)-equivariant, was optimized using the adaptive moment estimation with weight decay (AdamW) algorithm and trained for 500 epochs, ensuring uniformity in the format of the generated narratives regardless of the data source. The model's predictive accuracy was evaluated using the mean absolute deviation (MAD): mean absolute error (MAE) ratio, an important metric used to maintain the quality of the generated narratives.
Finally, the narrative creation involved a two-step process: first, converting extrapolated data into a structured material dictionary, and second, generating detailed descriptions of materials based on the dictionary content. This approach was designed to mirror the format of academic papers, where properties are reported, followed by a list of potential application areas. The generated narratives were subject to a thorough review by both human experts and GPT-4 to ensure their technical accuracy and detect any biases.
Validation of Generated Narratives
The technical validation of the generated narratives focused on identifying factual inaccuracies and improving clarity. Word cloud visualizations were used to examine the diversity and relevance of the texts derived from the JARVIS dataset. GPT-4 was utilized alongside human expert reviews to evaluate the narratives, focusing on technical accuracy, language structure, and content depth. A total of 1,067 randomly selected narratives were rigorously assessed by the human experts.
According to human evaluators, the sample of 1,067 narratives showed high organizational quality but fell short on content depth. Additionally, the research team employed GPTZero to identify AI-generated text, achieving over 92% detection accuracy and underscoring the risk of contamination with human-written content.
Material Discovery Enhancement
The natural language-material narratives developed here can initiate a new frontier in inverse material design, bridging the gap between natural language processing (NLP) and materials science. Approaches include innovative techniques such as multimodal learning for material inference, fine-tuning LLMs specifically for scientific applications, and using vector databases for in-context learning. Two novel metrics are proposed to assess understanding: predicting materials' properties (Mat2Props) and testing AI understanding through multiple-choice questions (Mat2MCQ). Recent evaluations showed that even advanced models struggle with certain tasks, highlighting ongoing gaps in AI understanding. Emphasizing intelligence-driven approaches will enhance material discovery while counteracting data shortages through synthetic data methods.
Conclusion
In summary, this work demonstrated how generating a diverse dataset of natural language-material narratives could significantly advance the exploration of solid-state materials through AI. The study demonstrated that integrating multimodal data sources with advanced LLMs facilitated the identification of suitable materials based on their inherent properties. Despite similar scoring between human experts and GPT-4, content depth remained challenging, indicating areas for future improvement. Ultimately, this approach opens the door to more refined and effective AI frameworks in materials discovery.