Background
The task of 3D scene reconstruction, especially from sparse-view images, has advanced significantly. Traditional methods like neural radiance fields (NeRF) and 3D Gaussian splatting (3DGS) offer detailed scene renders but require extensive camera pose data and dense input images. Techniques like structure-from-motion (SfM) help obtain camera poses but require dense video inputs, limiting real-world applications. Recent pose-free approaches attempt to jointly estimate poses and reconstruct scenes, but they are often sequential, leading to compounded errors in both tasks and reducing quality in NVS.
NoPoSplat addressed these limitations by eliminating pose dependency. The model directly predicts 3D Gaussians in a canonical space without pose input, which improves robustness for scenarios with limited image overlap. It does so by anchoring one view as a reference, thereby avoiding alignment errors that stem from transformations across local coordinate systems.
NoPoSplat also introduced a token-based embedding of camera intrinsics to resolve scale ambiguity in reconstructions. This approach significantly enhanced NVS quality and pose estimation accuracy, demonstrating scalability and effectiveness in real-world, user-provided image data.
Proposed Approach for 3D Scene Reconstruction
The proposed method used sparse, unposed multi-view images with camera intrinsic parameters to reconstruct 3D scenes by predicting Gaussian representations in a canonical 3D space. The approach employed a feed-forward network, mapping input images to 3D Gaussians characterized by position, opacity, rotation, scale, and spherical harmonics for scene geometry and appearance. This technique avoided the need for camera poses by directly producing a cohesive global scene representation, unlike traditional local-to-global transformations, which can be unreliable with sparse views.
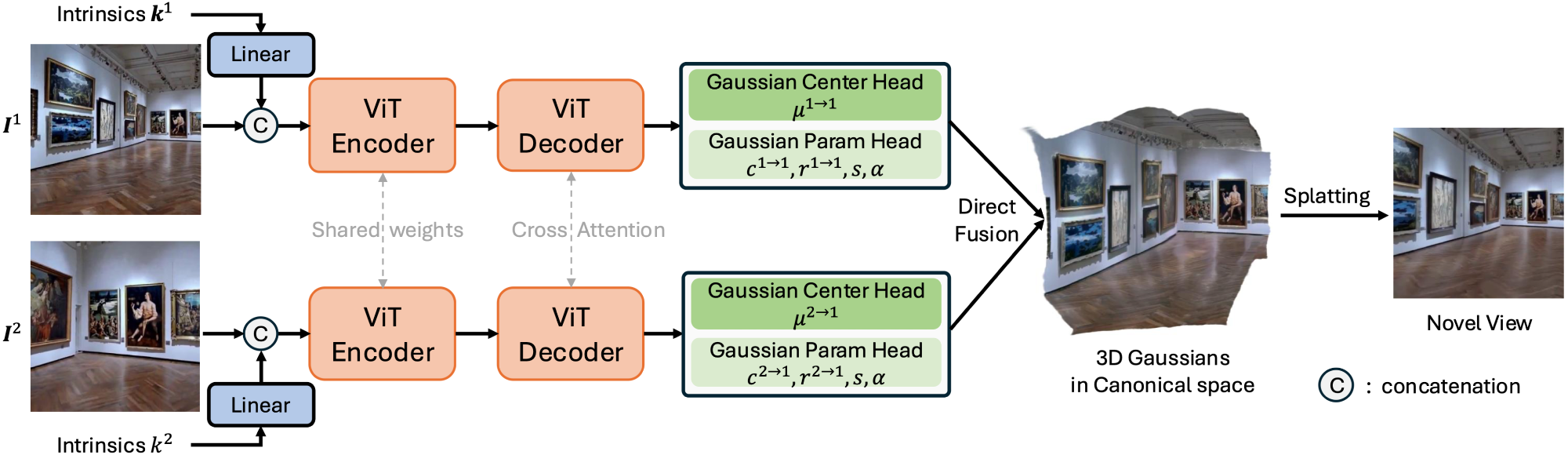 Overall Framework of NoPoSplat. Given sparse unposed images, our method directly reconstruct Gaussians in a canonical space from a feed-forward network to represent the underlying 3D scene. We also introduce a camera intrinsic token embedding, which is concatenated with the image tokens as input to the network to address the scale ambiguity problem. For simplicity, we use a two-view setup as an example.
Overall Framework of NoPoSplat. Given sparse unposed images, our method directly reconstruct Gaussians in a canonical space from a feed-forward network to represent the underlying 3D scene. We also introduce a camera intrinsic token embedding, which is concatenated with the image tokens as input to the network to address the scale ambiguity problem. For simplicity, we use a two-view setup as an example.
The pipeline comprised a vision transformer (ViT) encoder-decoder architecture that processed flattened image tokens and intrinsic parameters. The Gaussian parameters were predicted by two heads, one dedicated to Gaussian centers and the other to additional attributes, ensuring that texture details were preserved for accurate 3D reconstruction. Unlike methods requiring substantial overlap between input views, the ViT structure facilitated effective multi-view integration, even with limited content overlap.
The training involved rendering images from new viewpoints, guided by loss functions (mean squared error (MSE) and learned perceptual image patch similarity (LPIPS)). For pose estimation, the network first estimated relative camera poses through perspective-n-point (PnP) with random sample consensus (RANSAC), followed by photometric loss-based optimization.
The evaluation included aligning poses to ground truth to assess 3D scene reconstructions fairly. The method achieved high reconstruction quality by predicting directly in canonical space and incorporating camera intrinsics without needing exact pose alignment during real-world deployment.
Experimental Analysis
The authors presented an NVS approach for generating 3D representations from unposed images, improving upon current state-of-the-art (SOTA) methods. The model was evaluated on datasets featuring diverse scene types and camera motions, including RealEstate10k (RE10K), ACID, DTU, and ScanNet++.
RE10K comprised indoor real estate videos, ACID offered nature scenes from drones, and DL3DV extended outdoor content, introducing varied camera motions. The model’s capabilities were tested with varying input image overlaps and evaluated with standard metrics (peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), LPIPS), and relative pose accuracy.
 In-the-wild Data. We present the results of applying our method to in-the-wild data, including real-world photos taken with mobile phones and multi-view images extracted from videos generated by the Sora text-to-video model.
In-the-wild Data. We present the results of applying our method to in-the-wild data, including real-world photos taken with mobile phones and multi-view images extracted from videos generated by the Sora text-to-video model.
Compared to baselines, this method consistently outperformed both pose-required and pose-free models, especially in low-overlap settings, demonstrating enhanced synthesis quality and stability. Notably, it achieved high generalization in zero-shot tests on DTU and ScanNet++, outperforming SOTA methods on out-of-distribution data. This adaptability was attributed to the minimal geometric priors embedded in the network, allowing effective performance across scene types.
Further ablation studies revealed that the model’s 3D Gaussian predictions in canonical space enabled better image fusion and geometry reconstruction. Additionally, enhancements like RGB shortcuts and camera intrinsic embeddings were found critical in rendering quality.
Efficiency tests indicated that this model generated 3D Gaussians faster than SOTA models, achieving 66 frames per second (fps) on an RTX 4090 graphics processing unit (GPU). The model’s capability to handle in-the-wild unposed images opened potential applications for 3D scene generation from text or multi-view imagery, demonstrating its versatility and efficiency in NVS.
Conclusion
In conclusion, NoPoSplat represents a significant advancement in pose-free 3D scene reconstruction. By directly predicting 3D Gaussians in a canonical space, it effectively utilizes sparse, unposed multi-view images to improve NVS and pose estimation, particularly in scenarios with limited image overlap.
By leveraging a ViT architecture and incorporating camera intrinsic parameters, NoPoSplat demonstrated superior performance compared to traditional methods, offering high-quality reconstructions and real-time processing capabilities. Future work may explore extending this model to dynamic scenes, further broadening its application potential in 3D scene generation.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference:
- Preliminary scientific report.
Ye, B., Liu, S., Xu, H., Li, X., Pollefeys, M., Yang, M., & Peng, S. (2024). No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images. ArXiv. https://arxiv.org/abs/2410.24207