The paper demonstrated fine-tuning LLMs to generate, interpret, and interleave text and 3D mesh outputs, achieving comparable 3D generation quality to specialized models while maintaining strong text generation performance. Quantitative evaluations confirmed that the model retained competitive results across diverse metrics, such as MMLU and GSM8K.
Background
LLMs have excelled in text-based tasks like conversational artificial intelligence (AI) and code generation but remain limited to textual content, restricting their multimodal applications. While previous efforts expanded LLMs to integrate vision and language, no attempts have unified LLMs with 3D mesh generation.
Traditional 3D generation methods, such as DreamFusion and Magic3D, rely on numerical field representations and external tools, while auto-regressive models like PolyGen tokenize 3D data but lack language understanding, requiring training from scratch.
This paper addressed these gaps by introducing Llama-Mesh, which enabled LLMs to generate and interpret 3D meshes directly using plain text representations. The method employs the widely adopted OBJ format, with optimizations like vertex quantization into 64 bins to minimize token lengths while preserving geometric fidelity. By leveraging the OBJ format, Llama-Mesh avoided complex tokenization and vocabulary expansion, minimizing overhead.
A supervised fine-tuning dataset of text-3D pairs empowered LLMs to produce high-quality 3D meshes, interleaved text-3D dialogues, and natural language mesh descriptions. Training data included dialogues generated with rule-based templates and augmented conversational datasets like UltraChat, ensuring robust multimodal learning. This approach unified 3D and text modalities, achieving competitive 3D generation quality while retaining strong language capabilities, paving the way for conversational, intuitive 3D content creation.
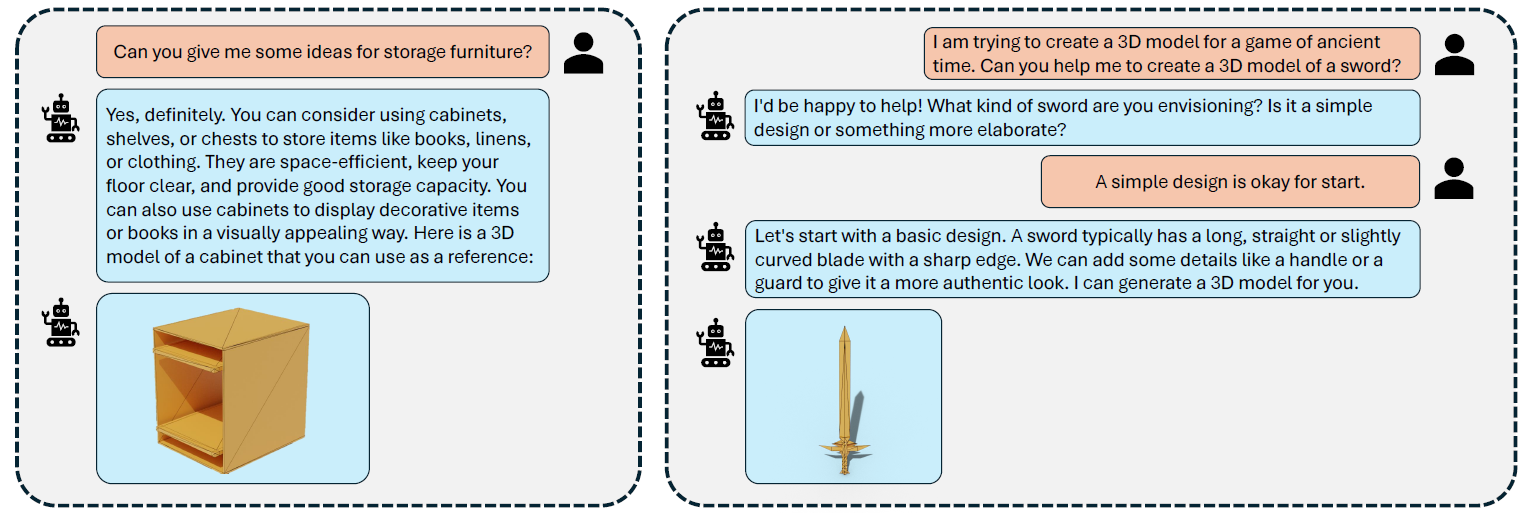 An illustration of our method, LLAMA-MESH, which enables the generation of 3D meshes from human instructions via a conversational interface. Users provide textual prompts, and the model responds with both text and 3D mesh outputs, facilitating interactive 3D content creation. LLAMA-MESH allows large language models to generate and interpret 3D meshes from text directly, seamlessly unifying language and 3D modalities within a single model.
An illustration of our method, LLAMA-MESH, which enables the generation of 3D meshes from human instructions via a conversational interface. Users provide textual prompts, and the model responds with both text and 3D mesh outputs, facilitating interactive 3D content creation. LLAMA-MESH allows large language models to generate and interpret 3D meshes from text directly, seamlessly unifying language and 3D modalities within a single model.
Proposed Approach and Implementation
Llama-Mesh introduced a novel approach to enabling LLMs to generate and interpret 3D meshes directly from textual descriptions. The core innovation was representing 3D meshes in the widely used OBJ file format, treating vertex coordinates and face definitions as plain text.
This avoided complex tokenizer modifications, reduced computational costs, and leveraged pre-trained LLMs’ existing capabilities. To address challenges such as sequence length and precision, the researchers quantized vertex coordinates into a fixed range of bins, reducing computational overhead while ensuring high-quality output.
The model was built on the LLaMA3.1-8B-Instruct, a pre-trained LLM tuned for instruction-based tasks. While LLaMA exhibited limited ability to generate basic 3D structures, fine-tuning was required to improve mesh complexity and quality.
A supervised fine-tuning (SFT) dataset was constructed using 3D objects from Objaverse. Around 125,000 meshes were prepared, with data augmented through random rotations and sorted by geometric coordinates to improve learning efficiency. This dataset combined rule-based templates, LLM-augmented dialogues, and general conversational data to teach the model mesh generation, understanding, and language tasks in a unified framework.
Through fine-tuning, Llama-Mesh gained the ability to generate high-quality 3D meshes, interpret mesh structures, and engage in interleaved text-3D dialogues. Despite its focus on 3D tasks, the model retained robust general language performance, as confirmed through extensive qualitative and quantitative evaluations. This integration of 3D and language modalities within a single model expanded the applications of LLMs to fields like virtual reality and robotics, enabling intuitive 3D content creation driven by natural language.
![More dialog results. LLAMA-MESH achieves several new tasks, including mesh generation and understanding, while completing other tasks like the original LLM. [...]: we omit some text to make the snippet fit into the page.](https://www.azoai.com/images/news/ImageForNews_5660_17322408108391988.jpg) More dialog results. LLAMA-MESH achieves several new tasks, including mesh generation and understanding, while completing other tasks like the original LLM. [...]: we omit some text to make the snippet fit into the page.
More dialog results. LLAMA-MESH achieves several new tasks, including mesh generation and understanding, while completing other tasks like the original LLM. [...]: we omit some text to make the snippet fit into the page.
Experimental Results and Analysis
The researchers evaluated Llama-Mesh, detailing its implementation, performance, and comparison with state-of-the-art methods. Llama-Mesh was trained on a filtered subset of the Objaverse dataset, containing meshes with up to 500 faces, to ensure computational feasibility. A total of 125 thousand (k) meshes were prepared, with vertex coordinates quantized into 64 bins to reduce token sequence lengths while retaining geometric fidelity.
Captions generated by Cap3D accompanied the meshes for training. Data augmentation, such as random rotations, enhances diversity. The model is fine-tuned on a combined dataset of mesh generation, mesh understanding, and general conversation data. The training utilized 32 A100 graphic processing units (GPU) over 21k iterations, employing full parameter fine-tuning with an AdamW optimizer and achieving rapid convergence without instabilities.
Llama-Mesh produced high-quality meshes with diverse topology. Generated meshes, evaluated by providing identical prompts, showed significant variation while satisfying the textual descriptions, which was crucial for applications requiring multiple design options.
Despite fine-tuning for 3D tasks, Llama-Mesh retained strong language and conversational capabilities. This capability was evaluated across multiple datasets, confirming competitive results in reasoning, instruction comprehension, and natural dialogue generation. Compared to MeshXL and Unique3D, Llama-Mesh achieved competitive mesh quality while preserving language understanding. Leveraging pre-trained LLMs reduced computational costs, significantly outperforming MeshXL in training efficiency, with GPU usage dropping from 6,000 hours for MeshXL to just 2,400 hours for Llama-Mesh.
Llama-Mesh’s quantization and context length constraints limited the complexity and fidelity of generated meshes. Furthermore, reliance on the Objaverse dataset restricted generalization, and future improvements could involve larger and more diverse datasets. Future work could address these issues by integrating larger models, more diverse datasets, and enhanced tokenization techniques.
Conclusion
In conclusion, Llama-Mesh introduced a groundbreaking framework that enabled LLMs to generate and interpret 3D meshes by representing them as plain text. Through fine-tuning on a curated 3D dataset, the model achieved high-quality mesh generation while retaining robust language abilities.
Llama-Mesh's integration of text and 3D modalities allowed for intuitive, conversational 3D content creation. By reducing computational costs and relying on pre-trained LLMs, this approach represents a major step toward multimodal generative AI. This innovation represented a significant step toward multimodal generative AI, with potential applications in fields like virtual reality, robotics, and design paving the way for seamless multimodal interactions. Future work could explore addressing context length constraints, improving mesh fidelity, and incorporating additional modalities like textures and dynamics.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference:
- Preliminary scientific report.
Wang, Z., Lorraine, J., Wang, Y., Su, H., Zhu, J., Fidler, S., & Zeng, X. (2024). LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models. ArXiv.org. DOI:10.48550/arXiv.2411.09595, https://arxiv.org/abs/2411.09595