Despite rapid advances, new evidence shows AI coding assistants remain prone to errors and inconsistencies, raising critical questions about their readiness for autonomous use in real-world development workflows.

Research: StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs. Image Credit: Jamie Jin / Shutterstock
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
New research from the University of Waterloo shows that artificial intelligence (AI) still struggles with some basic software development tasks, raising questions about how reliably AI systems can assist developers.
As Large Language Models (LLMs) are increasingly incorporated into software development, developers have struggled to ensure that AI-generated responses are accurate, consistent, and easy to integrate into larger development workflows.
Structured Outputs for LLM Code Generation
Previously, LLMs responded to software development prompts with free-form natural language answers. To address this problem, several AI companies, including OpenAI, Google and Anthropic, have introduced "structured outputs". These outputs force LLM responses to follow predefined formats such as JSON, XML, or Markdown, making them easier for both humans and software systems to read and process.
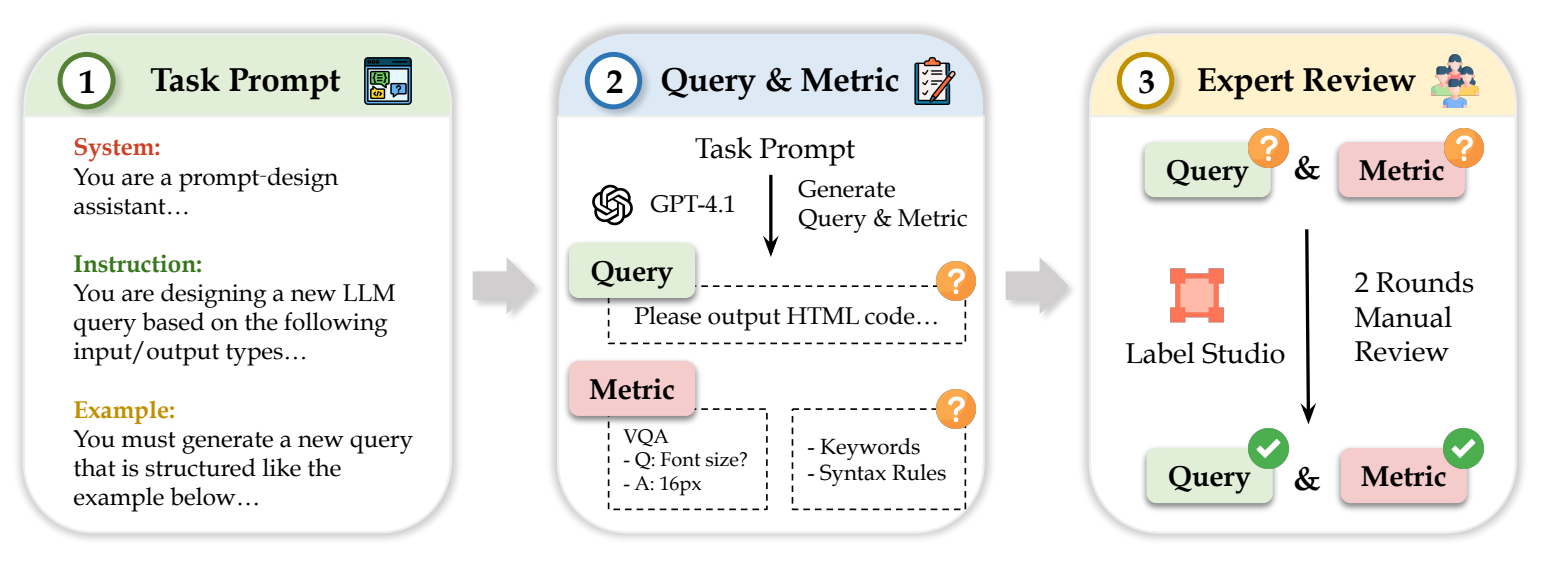
The overall designed annotation pipeline of StructEval dataset
Benchmark Results Show Limited Accuracy
A new benchmarking study from Waterloo, however, shows that the technology is not yet as reliable as many developers had hoped. Even the most advanced models achieved only about 75 per cent accuracy in the tests, while open-source models performed closer to 65 per cent.
The study evaluated 11 LLM models across 18 structured output formats and 44 tasks designed to assess how reliably the systems followed structured rules.
Performance Gaps in Complex AI Tasks
"With this kind of study, we want to measure not only the syntax of the code – that is, whether it's following the set rules – but also whether the outputs produced for various tasks were accurate," said Dongfu Jiang, a PhD student in computer science and co-first author on the research. "We found that while they do okay with text-related tasks, they really struggle on tasks involving image, video, or website generation."
Collaborative AI Benchmarking Research Effort
The study was a collaborative effort involving Waterloo's Jialin Yang, an undergraduate student, and Dr. Wenhu Chen, an assistant professor of computer science, and incorporated annotations from 17 other researchers at Waterloo and around the world.
"There have been a lot of similar benchmarking projects happening in our labs recently," Chen said. "At Waterloo, students often begin as annotators, then organize projects and create their own benchmarking studies. They're not just using AI in their studies – they're building, researching and evaluating it."
Need for Human Oversight in AI Coding
While LLM-structured outputs are an exciting step for software development, the researchers say the systems are not yet reliable enough to operate without human oversight. "Developers might have these agents working for them, but they still need significant human supervision," Jiang said.
Study Publication and Conference Presentation
The research, "StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs," appears in Transactions on Machine Learning Research and will be presented at ICLR 2026.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference:
- Preliminary scientific report.
Yang, J., Jiang, D., He, L., Siu, S., Zhang, Y., Liao, D., Li, Z., Zeng, H., Jia, Y., Wang, H., Schneider, B., Ruan, C., Ma, W., Lyu, Z., Wang, Y., Lu, Y., Do, Q. D., Jiang, Z., Nie, P., . . . Chen, W. (2025). StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs. ArXiv. https://arxiv.org/abs/2505.20139
 How is One Scientist Using Human Cognition to Build Better AI?
How is One Scientist Using Human Cognition to Build Better AI?