By capturing subtle emotional cues across text, audio, and video, R3DG sets a new benchmark for sentiment analysis, making emotion recognition smarter, faster, and more efficient.

Research: R3DG: Retrieve, Rank, and Reconstruction with Different Granularities for Multimodal Sentiment Analysis. Image Credit: Varavin88 / Shutterstock
Multimodal sentiment analysis (MSA) is an emerging technology that seeks to digitally automate the extraction and prediction of human sentiments from text, audio, and video. With advances in deep learning and human-computer interaction, research in MSA is receiving significant attention. However, when training MSA models or making predictions, aligning different modalities such as text, audio, and video for analysis can pose considerable challenges.
There are several ways of aligning various modalities in MSA. Most MSA methods align modalities either at the 'coarse-grained level' by grouping representations over different time steps or at the 'fine-grained level' by grouping modalities at each time step (step-by-step alignment). However, these approaches can fail to capture the individual variations in emotional expression or differences in contexts in which sentiments are expressed. To overcome this crucial limitation, researchers have now developed a framework for analyzing inputs of different modalities. Their study, which was recently published in the journal Research, shows that the framework 'Retrieve, Rank, and Reconstruction with Different Granularities (R3DG)' outperforms existing analysis methods and reduces the computational time required for analysis.
"Coarse-grained methods may miss subtle emotional cues like 'head nod', 'frown', or 'high pitch', especially in long videos. On the other hand, fine-grained alignment can lead to fragmented representations, where emotional events are divided into multiple time steps, creating data redundancy. Furthermore, these methods are computationally expensive due to the need for extensive attention-based alignment", explains Professor Fuji Ren of the University of Electronic Science and Technology of China, the lead researcher of the study.
Existing MSA approaches either average features over all time steps or align various features at each step, achieving one granularity of alignment at the maximum. In contrast, R3DG analyses representations at varying granularities, thus preserving potentially critical information and capturing emotional nuances across modalities. By aligning audio and video modalities to the text modality using representations at varying granularities, R3DG reduces computational complexity while enhancing the model's ability to capture nuanced emotional fluctuations. Its segmentation and selection of the most relevant audio and video features, combined with reconstruction to preserve critical information, contribute to more accurate and efficient sentiment prediction.
The researchers critically assessed the comparative performance of R3DG using five benchmark MSA datasets. R3DG demonstrated superior performance compared to existing methods across these datasets, with a substantial reduction in expended computational time. The findings suggest that the R3DG approach may be among the most efficient MSA methods.
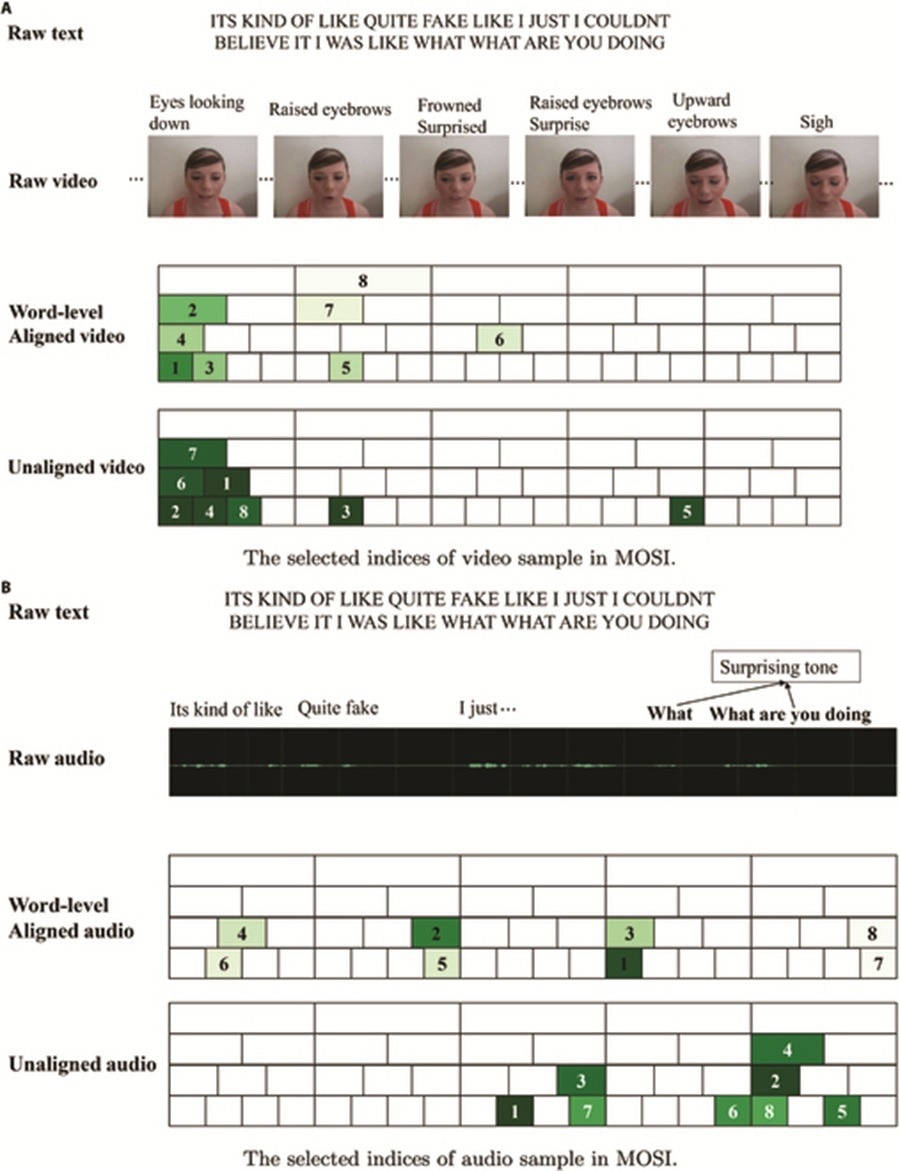
An example in MOSI. Given the text “ITS KIND OF LIKE QUITE FAKE LIKE I JUST I COULDNT BELIEVE IT I WAS LIKE WHAT WHAT ARE YOU DOING” and the corresponding video (A) and audio (B) files with both word-level aligned and unaligned settings, our R3DG framework identifies the most relevant segments. In the visual representation, boxes are labeled with numbers (e.g., 1, 2) indicating the top-k relevant parts, where darker colors signify higher similarity scores.
"Experimental results demonstrate that R3DG achieves state-of-the-art performance in multiple multimodal tasks, including sentiment analysis, emotion recognition, and humor detection, outperforming existing methods. Ablation studies further confirm R3DG's superiority, highlighting its robust performance despite the reduced computational cost", Dr. Jiawen Deng, the co-corresponding author, highlights the main findings of his study.
R3DG achieves modality alignment in just two steps: first between video and audio modalities, and then between their fused representation and text. This streamlined approach significantly reduces computational cost compared to most existing models. With its enhanced efficiency, R3DG demonstrates strong potential to drive the next generation of MSA.
"Looking ahead, future work will focus on automating the selection of modality importance and granularity, further enhancing R3DG's adaptability to diverse real-world applications", states Professor Ren, anticipating exciting future improvements to the MSA approach.
Source:
Journal reference:
- Yan Zhuang, Yanru Zhang, Jiawen Deng, Fuji Ren. R3DG: Retrieve, Rank, and Reconstruction with Different Granularities for Multimodal Sentiment Analysis. Research. 2025;8:0729. DOI: 10.34133/research.0729, https://spj.science.org/doi/10.34133/research.0729
 Agentic AI: Autonomy, Opportunity, and Emerging Risks
Agentic AI: Autonomy, Opportunity, and Emerging Risks